
Do you want to assess information that resides in Google BigQuery as element of an R workflow? Many thanks to the bigrquery R bundle, it is a very seamless working experience — once you know a few of little tweaks wanted to operate dplyr functions on this kind of information.
Very first, though, you are going to need to have a Google Cloud account. Take note that you are going to need to have your individual Google Cloud account even if the information is in a person else’s account and you really don’t system on storing your individual information.
How to established up a Google Cloud account
Several individuals already have common Google accounts for use with expert services like Google Travel or Gmail. If you really don’t have one particular yet, make positive to develop one particular.
Then, head to the Google Cloud Console at https://console.cloud.google.com, log in with your Google account, and develop a new cloud challenge. R veterans be aware: When initiatives are a good notion when functioning in RStudio, they’re necessary in Google Cloud.
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClick on the New Task choice in order to develop a new challenge.
You need to see the choice to develop a new challenge at the remaining aspect of Google Cloud’s leading navigation bar. Click on on the dropdown menu to the suitable of “Google Cloud Platform” (it might say “select project” if you really don’t have any initiatives already). Give your challenge a identify. If you have billing enabled already in your Google account you are going to be expected to pick out a billing account if you really don’t, that most likely will not look as an choice. Then click ”Create.”
 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGIf you really don’t like the default challenge ID assigned to your challenge, you can edit it just before clicking the Produce button.
If you really don’t like the challenge ID that is mechanically generated for your challenge, you can edit it, assuming you really don’t pick some thing that is already taken.
Make BigQuery simpler to discover
After you finish your new challenge set up, you are going to see a common Google Cloud dashboard that may well appear a bit mind-boggling. What are all these things and the place is BigQuery? You most likely really don’t need to have to worry about most of the other expert services, but you do want to be capable to quickly discover BigQuery in the midst of them all.
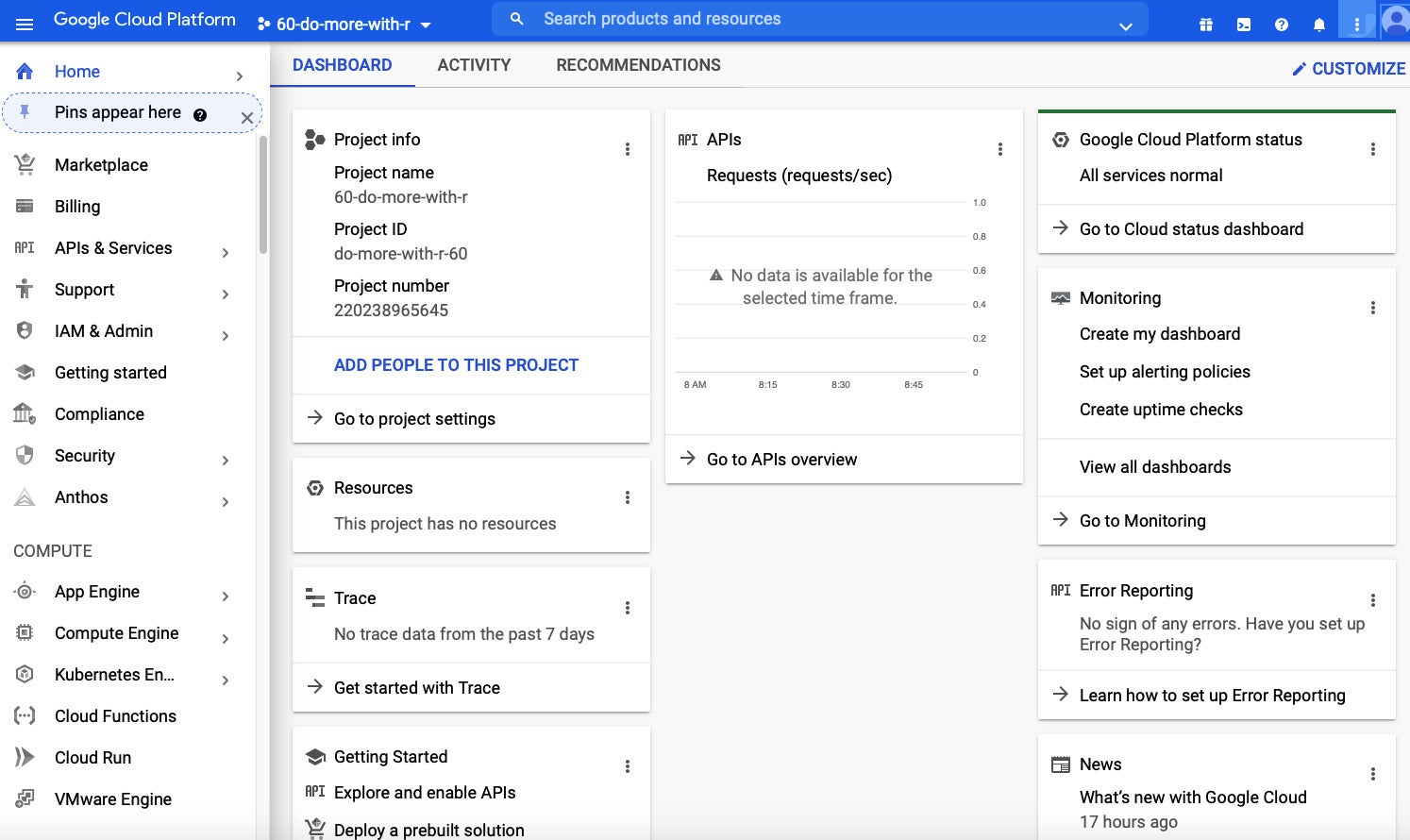 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGThe first Google Cloud dwelling screen can be a bit mind-boggling if you are seeking to use just one particular assistance. (I’ve because deleted this challenge.)
A person way is to “pin” BigQuery to the leading of your remaining navigation menu. (If you really don’t see a remaining nav, click the 3-line “hamburger” at the extremely leading remaining to open up it.) Scroll all of the way down, discover BigQuery, hover your mouse above it till you see a pin icon, and click the pin.
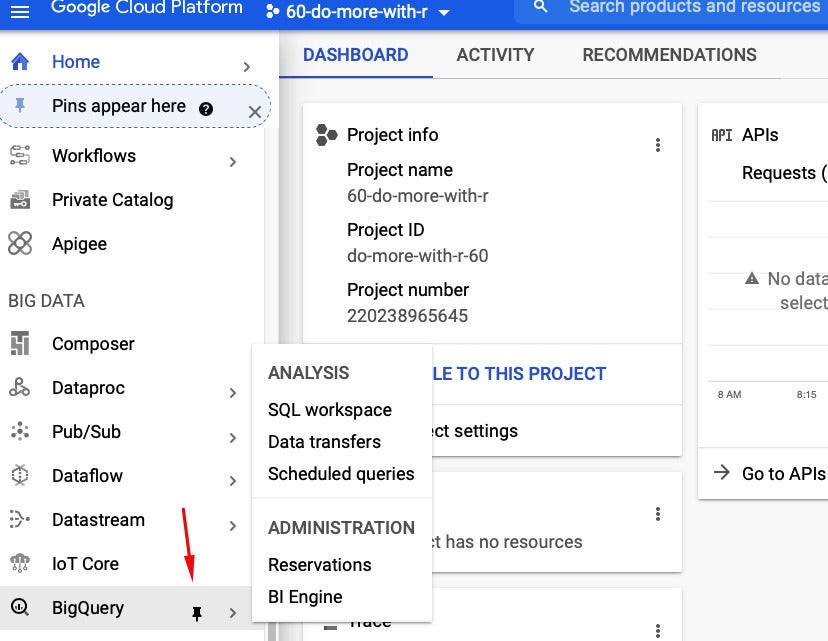 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGScroll down to the bottom of the remaining navigation in the primary Google Cloud dwelling screen to discover the BigQuery assistance. You can “pin” it by mousing above till you see the pin icon and then clicking on it.
Now BigQuery will generally present up at the leading of your Google Cloud Console remaining navigation menu. Scroll again up and you are going to see BigQuery. Click on on it, and you are going to get to the BigQuery console with the identify of your challenge and no information within.
If the Editor tab isn’t instantly seen, click on the “Compose New Query” button at the leading suitable.
Commence enjoying with public information
Now what? Men and women usually start out discovering BigQuery by enjoying with an obtainable public information established. You can pin other users’ public information initiatives to your individual challenge, which includes a suite of information sets collected by Google. If you go to this URL in the identical BigQuery browser tab you’ve been functioning in, the Google public information challenge need to mechanically pin itself to your challenge.
Many thanks to JohannesNE on GitHub for this suggestion: You can pin any information established you can accessibility by utilizing the URL construction shown beneath.
https://console.cloud.google.com/bigquery?p=challenge-id&site=challenge
If this doesn’t work, verify to make positive you’re in the suitable Google account. If you’ve logged into much more than one particular Google account in a browser, you may well have been sent to a distinct account than you predicted.
After pinning a challenge, click on the triangle to the remaining of the identify of that pinned challenge (in this situation bigquery-public-information) and you are going to see all information sets obtainable in that challenge. A BigQuery information established is like a standard database: It has one particular or much more information tables. Click on on the triangle subsequent to a information established to see the tables it incorporates.
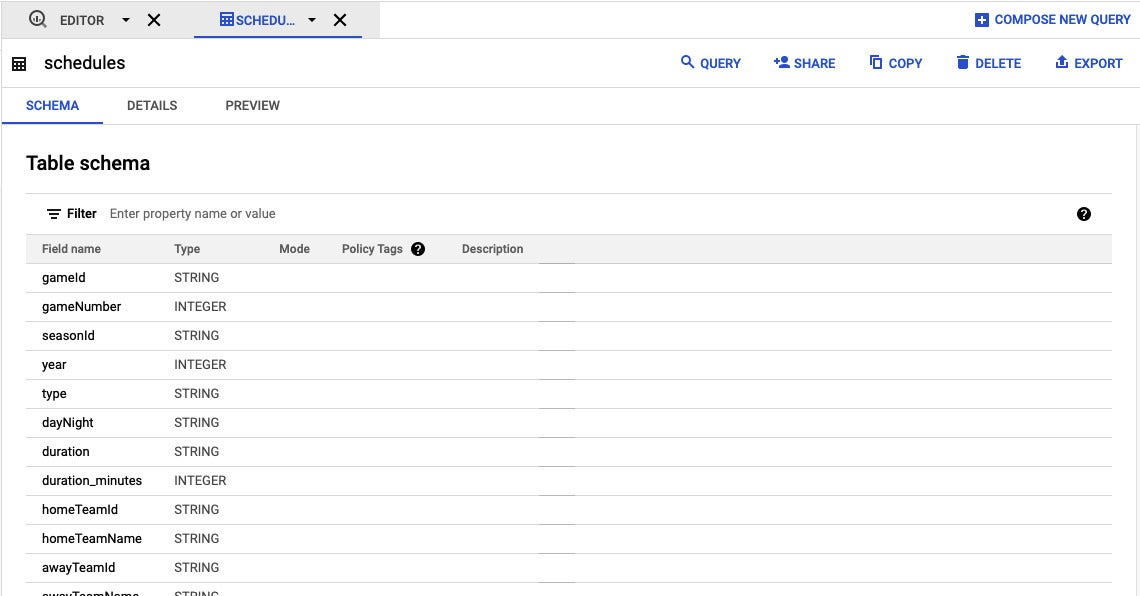 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGClicking on a table in the BigQuery world-wide-web interface allows you see its schema, along with a tab for previewing information.
Click on on the table identify to see its schema. There is also a “Preview” tab that allows you perspective some true information.
There are other, a lot less position-and-click approaches to see your information construction. But first….
How BigQuery pricing performs
BigQuery fees for the two information storage and information queries. When utilizing a information established produced by a person else, they fork out for the storage. If you develop and retail store your individual information in BigQuery, you fork out — and the amount is the identical regardless of whether you are the only one particular utilizing it, you share it with a couple of other individuals, or you make it public. (You get ten GB of totally free storage for every month.)
Take note that if you operate investigation on a person else’s information and retail store the outcomes in BigQuery, the new table becomes element of your storage allocation.
Enjoy your question costs!
The selling price of a question is primarily based on how substantially information the question procedures and not how substantially information is returned. This is crucial. If your question returns only the leading ten outcomes immediately after examining a 4 GB information established, the question will nevertheless use 4 GB of your information investigation quota, not basically the very small amount of money relevant to your ten rows of outcomes.
You get 1 TB of information queries totally free each month each added TB of information processed for investigation costs $five.
If you’re functioning SQL queries specifically on the information, Google advises hardly ever functioning a Select * command, which goes by means of all obtainable columns. In its place, Select only the precise columns you need to have to minimize down on the information that desires to be processed. This not only keeps your costs down it also can make your queries operate more rapidly. I do the identical with my R dplyr queries, and make positive to pick out only the columns I need to have.
If you’re thinking how you can perhaps know how substantially information your question will use just before it runs, there is an quick remedy. In the BigQuery cloud editor, you can sort a question devoid of functioning it and then see how substantially information it will process, as shown in the screenshot beneath.
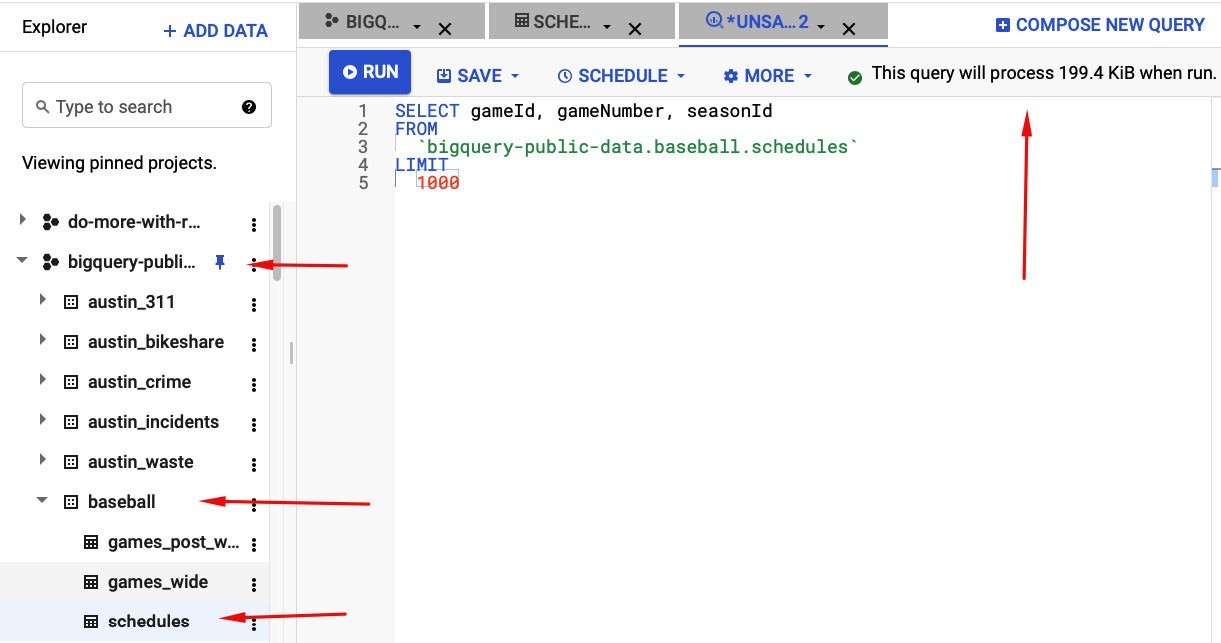 Screenshot by Sharon Machlis, IDG
Screenshot by Sharon Machlis, IDGWorking with the BigQuery SQL editor in the world-wide-web interface, you can discover your table below its information established and challenge. Typing in a question devoid of functioning it demonstrates how substantially information it will process. Keep in mind to use `projectname.datasetname.tablename` in your question
Even if you really don’t know SQL, you can do a easy SQL column choice to get an notion of the charge in R, because any added filtering or aggregating doesn’t lower the amount of money of information analyzed.
So, if your question is functioning above 3 columns named columnA, columnB, and columnC in table-id, and table-id is in dataset-id which is element of challenge-id, you can basically sort the subsequent into the question editor:
Select columnA, columnB, columnC FROM `project-id.dataset-id.table-id`
Don’t operate the question, just sort it and then search at the line at the leading suitable to see how substantially information will be employed. Whatsoever else your R code will be accomplishing with that information shouldn’t issue for the question charge.
In the screenshot over, you can see that I’ve picked 3 columns from the schedules table, which is element of the baseball information established, which is element of the bigquery-public-information challenge.
Queries on metadata are totally free, but you need to have to make positive you’re thoroughly structuring your question to qualify for that. For example, utilizing Select Depend(*) to get the range of rows in a information established isn’t billed.
There are other things you can do to restrict costs. For much more strategies, see Google’s “Controlling costs in BigQuery” site.
Do I need to have to enter a credit history card to use BigQuery?
No, you really don’t need to have a credit history card to start out utilizing BigQuery. But devoid of billing enabled, your account is a BigQuery “sandbox” and not all queries will work. I strongly recommend including a billing supply to your account even if you’re extremely not likely to exceed your quota of totally free BigQuery investigation.
Now — lastly! — let’s search at how to tap into BigQuery with R.
Join to BigQuery information established in R
I’ll be utilizing the bigrquery bundle in this tutorial, but there are other alternatives you may well want to take into account, which includes the obdc bundle or RStudio’s qualified motorists and one particular of its company products.
To question BigQuery information with R and bigrquery, you first need to have to established up a link to a information established utilizing this syntax:
library(bigrquery)
con <- dbConnect(
bigquery(),
project = challenge_id_made up of_the_information,
dataset = database_identify
billing = your_challenge_id_with_the_billing_supply
)
The first argument is the bigquery() purpose from the bigrquery bundle, telling dbConnect that you want to join to a BigQuery information supply. The other arguments define the challenge ID, information established identify, and billing challenge ID.
(Relationship objects can be named very substantially nearly anything, but by convention they’re usually named con.)
The code beneath hundreds the bigrquery and dplyr libraries and then generates a link to the schedules table in the baseball information established.
bigquery-public-information is the challenge argument mainly because which is the place the information established life. my_challenge_id is the billing argument mainly because my project’s quota will be “billed” for queries.
library(bigrquery)
library(dplyr)
con <- dbConnect(
bigrquery::bigquery(),
challenge = "bigquery-public-information",
dataset = "baseball",
billing = "my_challenge_id"
)
Absolutely nothing substantially occurs when I operate this code besides producing a link variable. But the first time I consider to use the link, I’ll be asked to authenticate my Google account in a browser window.
For example, to listing all obtainable tables in the baseball information established, I’d operate this code:
dbListTables(con)
# You will be asked to authenticate in your browser
How to question a BigQuery table in R
To question one particular precise BigQuery table in R, use dplyr’s tbl() purpose to develop a table object that references the table, this kind of as this for the schedules table utilizing my recently produced link to the baseball information established:
skeds <- tbl(con, "schedules")
If you use the foundation R str() command to take a look at skeds’ construction, you are going to see a listing, not a information body:
str(skeds) Checklist of 2 $ src:Checklist of 2 ..$ con :Formal class 'BigQueryConnection' [bundle "bigrquery"] with 7 slots .. .. ..@ challenge : chr "bigquery-public-information" .. .. ..@ dataset : chr "baseball" .. .. ..@ billing : chr "do-much more-with-r-242314" .. .. ..@ use_legacy_sql: logi Phony .. .. ..@ site_size : int 10000 .. .. ..@ tranquil : logi NA .. .. ..@ bigint : chr "integer" ..$ disco: NULL ..- attr(*, "class")= chr [1:4] "src_BigQueryConnection" "src_dbi" "src_sql" "src" $ ops:Checklist of 2 ..$ x : 'ident' chr "schedules" ..$ vars: chr [1:16] "gameId" "gameNumber" "seasonId" "12 months" ... ..- attr(*, "class")= chr [1:3] "op_foundation_distant" "op_foundation" "op" - attr(*, "class")= chr [1:five] "tbl_BigQueryConnection" "tbl_dbi" "tbl_sql" "tbl_lazy" ...
Fortuitously, dplyr functions this kind of as glimpse() usually work very seamlessly with this sort of object (class tbl_BigQueryConnection).
Running glimpse(skeds) will return typically what you assume — besides it doesn’t know how several rows are in the information.
glimpse(skeds)
Rows: ??
Columns: 16
Database: BigQueryConnection
$ gameId"e14b6493-9e7f-404f-840a-8a680cc364bf", "1f32b347-cbcb-4c31-a145-0e…
$ gameNumber1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ seasonId"565de4be-dc80-4849-a7e1-54bc79156cc8", "565de4be-dc80-4849-a7e1-54…
$ 12 months2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2016, 2…
$ sort"REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG", "REG…
$ dayNight"D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D", "D…
$ duration"3:07", "3:09", "2:forty five", "3:forty two", "2:44", "3:21", "2:fifty three", "2:fifty six", "3:…
$ duration_minutes187, 189, a hundred sixty five, 222, 164, 201, 173, 176, a hundred and eighty, 157, 218, a hundred and sixty, 178, 20…
$ homeTeamId"03556285-bdbb-4576-a06d-42f71f46ddc5", "03556285-bdbb-4576-a06d-42…
$ homeTeamName"Marlins", "Marlins", "Braves", "Braves", "Phillies", "Diamondbacks…
$ awayTeamId"55714da8-fcaf-4574-8443-59bfb511a524", "55714da8-fcaf-4574-8443-59…
$ awayTeamName"Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cubs", "Cu…
$ startTime2016-06-26 17:ten:00, 2016-06-25 twenty:ten:00, 2016-06-eleven twenty:ten:00, 201…
$ attendance27318, 29457, 43114, 31625, 28650, 33258, 23450, 32358, 46206, 4470…
$ position"closed", "closed", "closed", "closed", "closed", "closed", "closed…
$ produced2016-ten-06 06:25:fifteen, 2016-ten-06 06:25:fifteen, 2016-ten-06 06:25:fifteen, 201…
That tells me glimpse() may well not be parsing by means of the complete information established — and suggests there is a good probability it is not functioning up question fees but is as an alternative querying metadata. When I checked my BigQuery world-wide-web interface immediately after functioning that command, there certainly was no question cost.
BigQuery + dplyr investigation
You can operate dplyr instructions on table objects practically the identical way as you do on standard information frames. But you are going to most likely want one particular addition: piping outcomes from your common dplyr workflow into the acquire() purpose.
The code beneath utilizes dplyr to see what decades and dwelling groups are in the skeds table object and saves the outcomes to a tibble (particular sort of information body employed by the tidyverse suite of packages).
obtainable_groups <- select(skeds, homeTeamName) {36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}>{36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}
distinctive() {36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}>{36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}
acquire()
Finish
Billed: ten.forty nine MB
Downloading 31 rows in 1 webpages.
Pricing be aware: I checked the over question utilizing a SQL statement seeking the identical facts:
Select Unique `homeTeamName`
FROM `bigquery-public-information.baseball.schedules`
When I did, the BigQuery world-wide-web editor showed that only 21.1 KiB of information were being processed, not much more than ten MB. Why was I billed so substantially much more? Queries have a ten MB minimal (and are rounded up to the subsequent MB).
Aside: If you want to retail store outcomes of an R question in a momentary BigQuery table as an alternative of a area information body, you could insert compute(identify = “my_temp_table”) to the stop of your pipe as an alternative of acquire(). Nevertheless, you’d need to have to be functioning in a challenge the place you have permission to develop tables, and Google’s public information challenge is definitely not that.
If you operate the identical code devoid of acquire(), this kind of as
obtainable_groups <- select(skeds, homeTeamName) {36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}>{36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}
distinctive()
you are preserving the question and not the outcomes of the question. Take note that obtainable_groups is now a question object with classes tbl_sql, tbl_BigQueryConnection, tbl_dbi, and tbl_lazy (lazy which means it will not operate except precisely invoked).
You can operate the saved question by utilizing the object identify by itself in a script:
obtainable_groups
See the SQL dplyr generates
You can see the SQL becoming generated by your dplyr statements with present_question() at the stop of your chained pipes:
pick out(skeds, homeTeamName) {36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}>{36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}
distinctive() {36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}>{36a394957233d72e39ae9c6059652940c987f134ee85c6741bc5f1e7246491e6}
present_question()
Select Unique `homeTeamName`
FROM `schedules`
You can minimize and paste this SQL into the BigQuery world-wide-web interface to see how substantially information you are going to use. Just keep in mind to change the simple table identify this kind of as `schedules` to the syntax `project.dataset.tablename` in this situation, `bigquery-public-information.baseball.schedules`.
If you operate the identical precise question a next time in your R session, you will not be billed yet again for information investigation mainly because BigQuery will use cached outcomes.
Run SQL on BigQuery in just R
If you’re cozy composing SQL queries, you can also operate SQL instructions in just R if you want to pull information from BigQuery as element of a much larger R workflow.
For example, let’s say you want to operate this SQL command:
Select Unique `homeTeamName` from `bigquery-public-information.baseball.schedules`
You can do so in just R by utilizing the DBI package’s dbGetQuery() purpose. Below is the code:
sql <- "SELECT DISTINCT homeTeamName from bigquery-public-data.baseball.schedules" library(DBI) my_results <- dbGetQuery(con, sql) Complete Billed: 10.49 MB Downloading 31 rows in 1 pages
Take note that I was billed yet again for the question mainly because BigQuery does not take into account one particular question in R and one more in SQL to be accurately the identical, even if they’re seeking the identical information.
If I operate that SQL question yet again, I will not be billed.
my_results2 <- dbGetQuery(con, sql) Complete Billed: 0 B Downloading 31 rows in 1 pages.
BigQuery and R
After the one particular-time first set up, it is as quick to assess BigQuery information in R as it is to operate dplyr code on a area information body. Just continue to keep your question costs in head. If you’re functioning a dozen or so queries on a ten GB information established, you will not appear close to hitting your 1 TB totally free month to month quota. But if you’re functioning on much larger information sets day by day, it is worth seeking at approaches to streamline your code.
For much more R strategies and tutorials, head to my Do Far more With R page.
Copyright © 2021 IDG Communications, Inc.